Deep Learning Introduction
Deep learning is a subset of machine learning where computers can learn and make intelligent decisions themselves. They accomplish this by replicating how the neurons in our brain work. Therefore, it is imperative to understand how a neuron works.
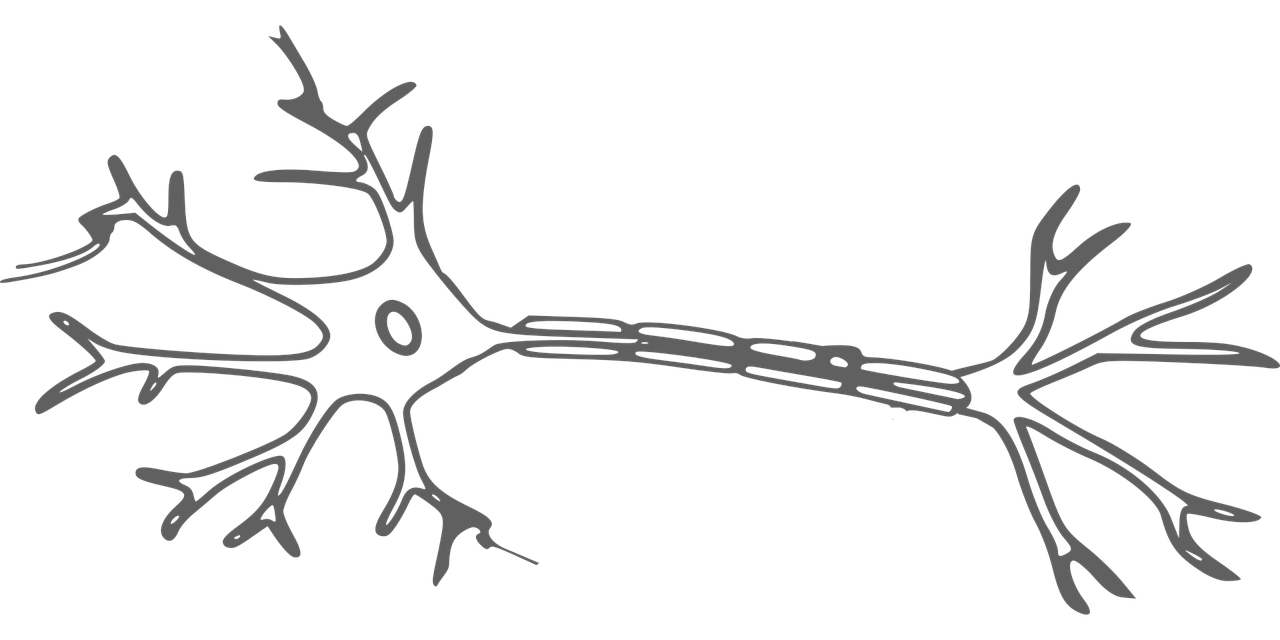
<A picture of a neuron>
The image above is a drawing of a neuron. The arms sticking out at the front part of the neuron are called dendrites. The body linking all the Dendrites together is called the soma. Soma contains the nucleus of the neuron. The middle portion that is sticking out of the soma is called the Axon. The end portion of the neuron is called the Synapse. Our brain has 100 billion neurons.
The dendrites receive electrical impulses which carry information or data from Synapse from other neurons. The Dendrites then pass the data to the soma. In the nucleus, electrical impulses, or the data, are processed by combining them, and then they are sent to the Axon. The Axon then carries the information to the Synapse. This process repeats, and the output of the Synapse becomes the input to the other neurons.
Similar to how the biological neuron functions, the artificial neuron takes in data from other neurons, processes them, and then outputs them for the other neurons.
Artificial Neural Network
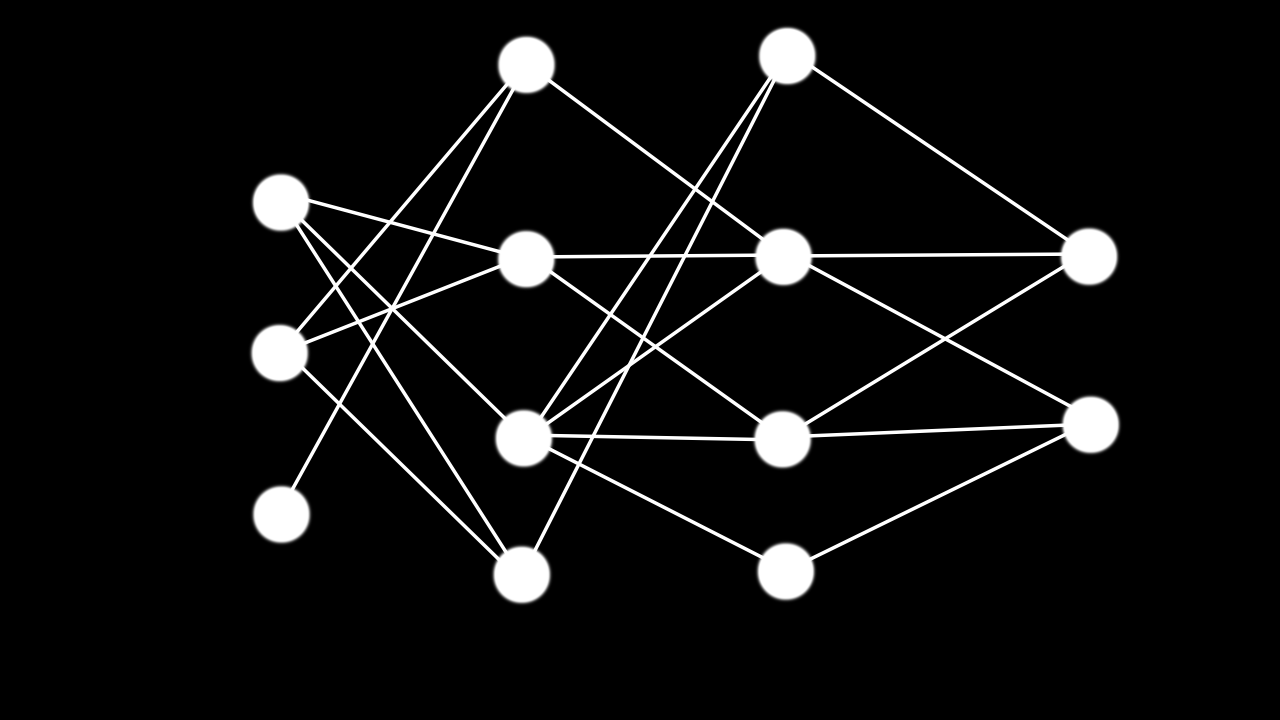
<An image of an artificial neural network>
An artificial neural network, as shown above, contains three components, the input layer, the output layer, and hidden layers. The layer on the extreme left is the input layer, and then the layer on the extreme right is the output layer. The layers in the middle are called the hidden layers. For the model to be classified as a deep learning model, we need to have two or more hidden layers.
The three key topics that are required to understand artificial neural networks are activation functions, forward propagation, and backpropagation. Before we dive into those topics, there is some terminology that needs to be understood first. They are weights and biases. Weights decide how much influence the input will have by multiplying it with the input value. Gradient Descent is one way to determine the value for the weights. Biases are an additional input to the neuron to ensure that there is an activation in the neuron when all the inputs are zero.
Activation Functions
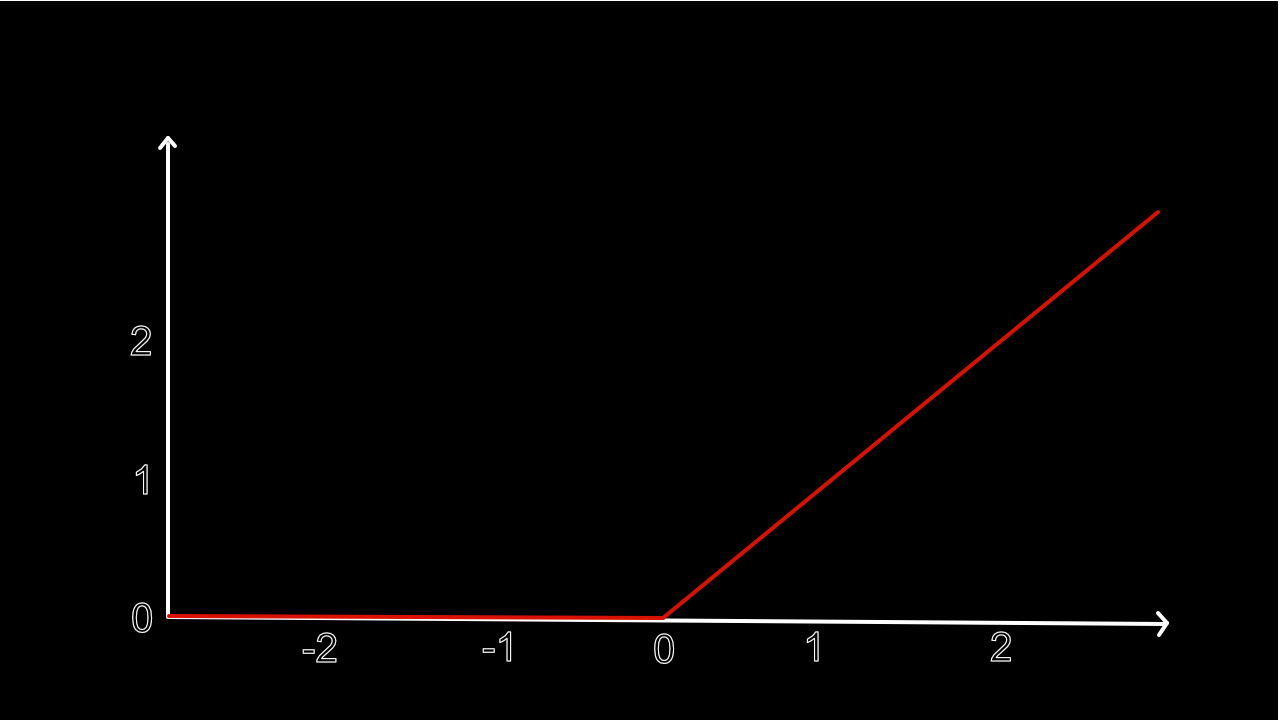
<A graph of ReLU Activation Function>
Activation functions are used to decide whether a neuron should be activated. Some common functions are Softmax, ReLU, sigmoid, etc. Sigmoid function will cause the Vanishing Gradient problem and hence, it is not being used. ReLU can only be used in the hidden layer as anything that is negative will result in being 0. Softmax is used in classification problems and is ideally used in the output layer.
Forward Propagation
Forward propagation is about the data passing through the neurons from the input layers to the output layers. A neuron takes in data from the previous neuron, let’s give it a value of 0.5. First, they will multiply this value with the weights as mentioned above, assuming a value of 0.1. After multiplying both values together, we need to add the biases, assuming it is 0.2. The weighted sum of the neuron will be 0.5 * 0.1 + 0.2 = 0.25. Simply utilising this value will limit the tasks that the neural network can perform. This is where the activation functions come in. Mapping the weighted sum to a nonlinear space will result in better processing of data. For instance, the ReLU function. After applying max(0,0.25), the output now is 0.25.
Backpropagation
Backpropagation is used to optimize their weights and biases. It starts by calculating the error between the predicted value and the actual value. The next step is to propagate this error back into the network and use it to perform gradient descent on different weights and biases.
Some knowledge of differentiation is required. Assuming the output layer neuron’s weighted sum is y, the nucleus is z; the weight is w, and the bias is b. Step one is to calculate the error between the actual value and the y value. We will call this e The next step is to update the w and b.
In order to update w and b, we need to use differentiation. We will start by calculating for w. We know the e value is the derivative of e with respect to y. y is the derivative of y with respect of z. z is the derivative of z with respect to w. So now to compute the derivative of e with respect to w, we can multiply derivate of e with respect to y, the derivative of y with respect to z, the derivative z with respect to w.
Now, we will start by calculating the b. b is the same as the above except for the z is the derivate of z with respect to w, we need to change to b. This will yield the result of 1. So now to compute the derivative of e with respect to w, we can multiply derivate of e with respect to y, derivative of y with respect to z, derivative z with respect to b (which is 1).
If you have more neurons at the front, you will need to update both the weights and biases of all the neurons beforehand using the derivative above but adding more derivatives until you have arrived at the w and b for the previous neuron. Once you have adjusted all the neuron’s weight and bias, it will do another round of forward propagation, calculate the error, do backpropagation until the number of epoch has been completed or until the error is within a pre-defined threshold.
Examples of Neural Networks
Neural Networks are split between supervised and unsupervised. There are three main types of neural networks, Artificial Neural Network (ANN), Convolutional Neural Networks (CNN), and Recurrent Neural Network. We will talk about CNN. CNN takes inputs as images and allows us to solve problems that involve image recognition for instance. A CNN architecture contains an Input layer, Output layer, Convolution, Convolution layer, Max Pooling, Pooling layer.
Input Layer
For an RGB image, there are 3 layers, Red, Green, and Blue. Each pixel’s colour is generated by combining these 3 values.
Convolutional Layers
The convolutional layer’s goal is to reduce the parameters, which can become computationally expensive and may cause overfitting. The aim is to apply a filter over each layer and output this new value into a new matrix. We can apply more than one filter. An activation function could also be used at the output here.
Pooling Layers
The pooling layer’s goal is to reduce the spatial dimensions of the data. The way it is implemented is like the convolutional layers in the sense that a filter (assuming 3 x 3) will go over the layer. However, since the goal is to reduce the spatial dimensions of the data, one method is to extract out the highest value and store it inside the new matrix.
Deep Learning Frameworks
The framework to implement your first deep learning is Keras. It is built on top of TensorFlow, providing the developer with a balance of tuning the parameters and easy-to-use interfaces. I prefer PyTorch, but the most popular framework by far is TensorFlow.
Deep Learning Applications

<An image of Tesla Car>
Deep learning has many great potentials, with the most notable one being self-driving cars that are used in Tesla. At the time of writing, Tesla’s HW3 (Hardware version 3) uses 8 surrounding cameras and 12 ultrasonic sensors. Using their in-house design SoC (Bos, 2019), the SoC can process roughly 144 TOPs (Terra operations per second). This enables Tesla to quickly classify the information from the neural networks at a very fast rate.
Another cool project is https://thispersondoesnotexist.com/. This website, created by Phillip Wang, allows users to generate realistic-looking photos of people that don’t exist. It utilises StyleGAN2, which is a generative adversarial network.
Conclusion
This blog post barely scratches the surface of the field of deep learning, but I hope that I have gotten your interest in this field. With the ease of getting hold of powerful hardware (cloud, desktop, GPU) and the massive amount of open-source dataset, using deep learning to solve real-world problems is getting easier by the day. Try and start a deep learning project today!
Credits
Hale, J. (2019, October 24). Deep Learning Framework Power Scores 2018 - Towards Data Science. Medium. https://towardsdatascience.com/deep-learning-framework-power-scores-2018-23607ddf297a
Bos, C. (2019, June 16). Tesla’s New HW3 Self-Driving Computer — It’s A Beast (CleanTechnica Deep Dive). CleanTechnica. https://cleantechnica.com/2019/06/15/teslas-new-hw3-self-driving-computer-its-a-beast-cleantechnica-deep-dive/
Wikipedia contributors. (2021, May 23). StyleGAN. Wikipedia. https://en.wikipedia.org/wiki/StyleGAN